Why FSRS Is the Most Advanced Spaced Repetition System (And Why You Should Care)
An In-Depth Look at the Algorithm Used by MintDeck
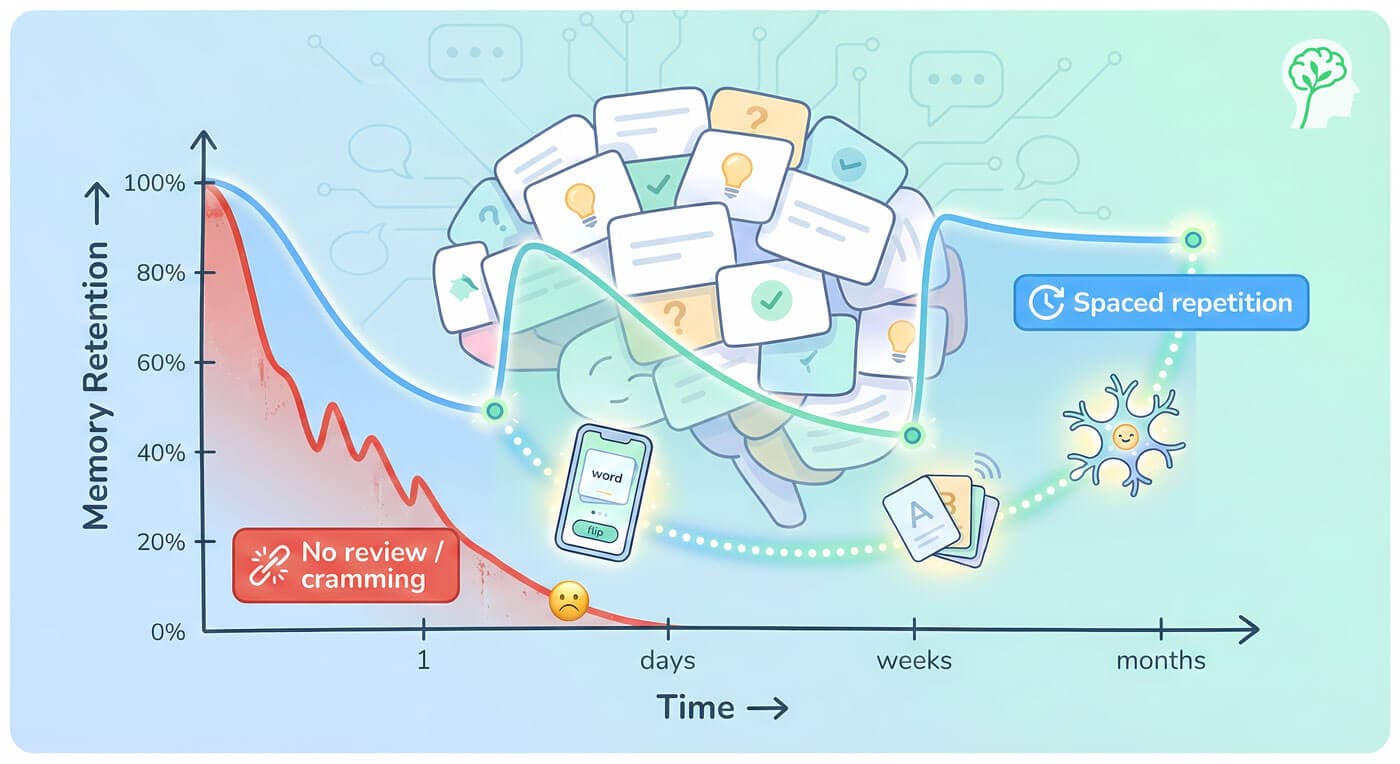
For decades, the SuperMemo 2 (SM-2) method dominated the spaced repetition landscape. Developed in the 1980s, it became the gold standard for flashcard apps, medical school decks, and language learners worldwide. But the field has evolved. Today, a new generation of approaches—led by the Free Spaced Repetition Scheduler (FSRS)—is fundamentally changing how millions of learners study more efficiently and retain information better.
If you've ever felt frustrated by inefficient review schedules, wasted study time on cards you already know, or struggled to maintain a sustainable learning pace, the answer might lie in understanding how modern scheduling systems work. This is where FSRS steps in, offering a smarter, more adaptive approach to learning.
What Is FSRS, and Why Does It Matter?
FSRS stands for "Free Spaced Repetition Scheduler." Unlike older systems that rely on static formulas created decades ago, this approach uses machine learning to continuously adapt to your personal memory patterns. Instead of asking you to manually configure dozens of settings, it analyzes your review history and automatically optimizes its parameters specifically for how your brain works.
This fundamental shift from static to adaptive scheduling represents one of the biggest advances in educational technology in recent memory. Independent benchmarks show that this system with default parameters outperforms SM-2 in 91.9% of cases. When parameters are optimized for individual users, it surpasses the older method in 99% of cases—meaning only 1 in 100 learners would be better off using the classic approach.
But why should you care about this technical distinction? Because it directly impacts your study life. Users of this system report needing 20-30% fewer review sessions per day while maintaining the same how-much-you-remember rates. For students preparing for medical licensing exams, professionals learning new languages, or anyone committed to lifelong learning, that efficiency translates to hours saved each month.
The Three-Component Model: Understanding How Modern Scheduling Works
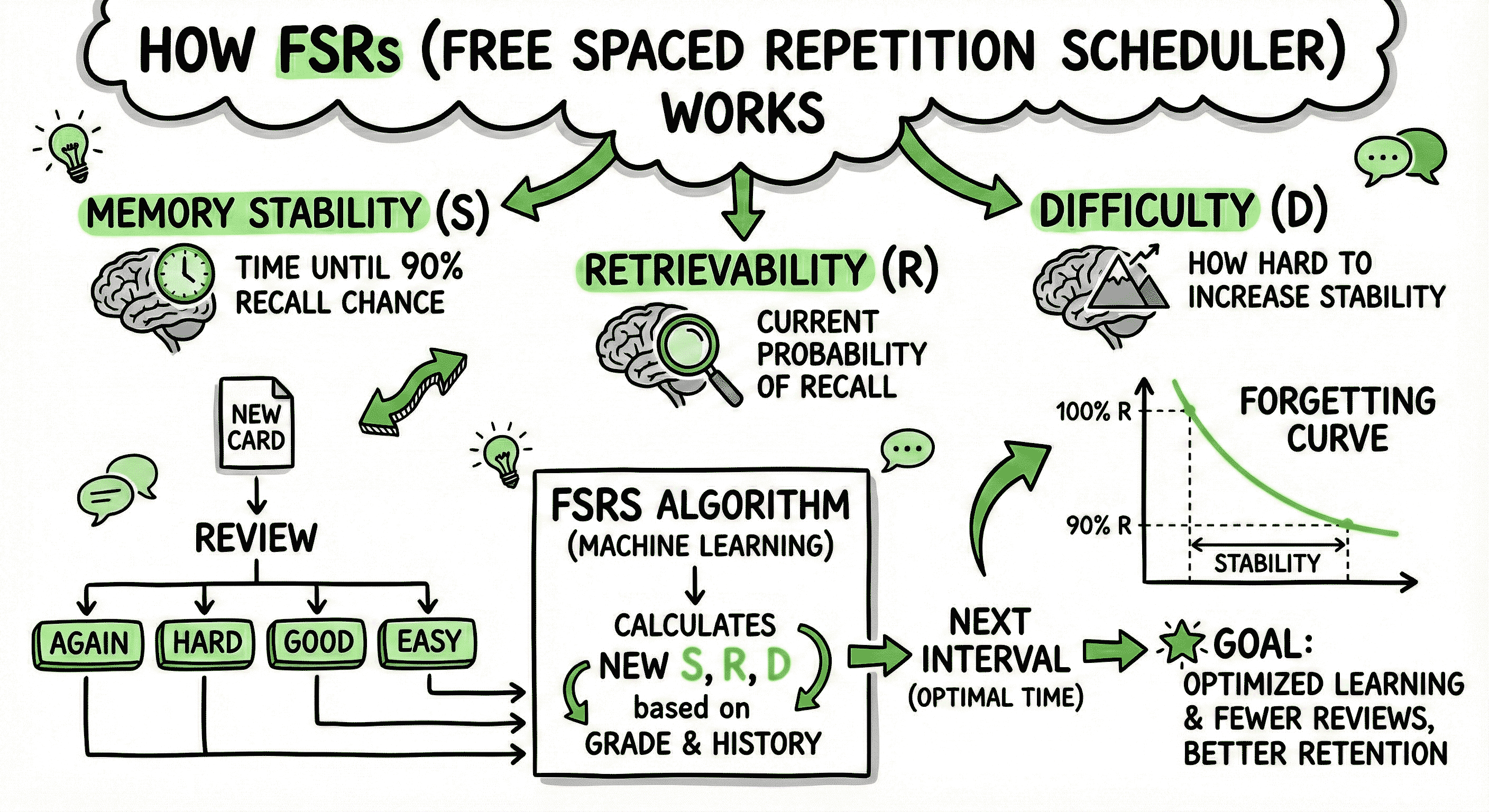
At its core, this system is based on the "Three Component Model of Memory," which describes three essential variables that determine how well you'll remember information:
1. Difficulty (D)
Difficulty is a per-card metric (scaled 1-10) that represents how inherently hard it is to recall that specific piece of information. A flashcard asking you to recall the Spanish word for "bread" might have low difficulty, while a card asking you to explain quantum entanglement would have high difficulty.
In this system, your performance on a card helps the engine estimate its true difficulty. If you consistently struggle with a particular card, even after multiple exposures, the scheduler recognizes it as genuinely challenging and schedules reviews accordingly. This is fundamentally different from older systems, where you manually rate ease on a numeric scale.
2. Stability (S)
Memory stability measures how long your brain can retain information before it begins to fade. Technically, stability is defined as the number of days required for your recall probability to decline from 100% (certain recall) to 90% (the typical target threshold used in spaced repetition).
A card with high stability—say 180 days—means you could realistically remember it perfectly for months without review. A card with low stability—perhaps 3 days—means you need to review it frequently to maintain how-much-you-remember.
The brilliance of this modern approach lies in how it updates stability. Every time you review a card and either succeed or fail, the system recalculates stability based on your actual performance. This is where machine learning becomes crucial: it uses neural networks and sophisticated curve-fitting techniques to determine exactly how much each review should adjust your card's stability. Unlike older formulas that rely on rigid calculations, this method's adjustments are contextual and personalized.
3. Retrievability (R)
Retrievability is your probability of successfully recalling a card at any given moment. It's the most dynamic variable in this system—it changes daily based on how much time has passed since your last review, regardless of whether you've actually reviewed the card again.
This approach calculates retrievability using a mathematical power function (rather than the exponential function used in classical memory research). This might sound esoteric, but the practical implication is profound: the scheduler can predict your current recall probability with remarkable accuracy, even without testing you. It "knows" that if a card has stability of 30 days and you last reviewed it 15 days ago, your retrievability is approximately 95%.
This predictive power is essential because it allows the system to answer the fundamental question of spaced repetition: When should I review this card next? The answer is: whenever your retrievability would drop to your target how-much-you-remember level.
How Modern Scheduling Differs from SM-2: The Technical Advantages
To truly appreciate why this approach represents a leap forward, it helps to understand specifically how it outperforms the 40-year-old SuperMemo method.
SM-2's Limitations
The older system uses a relatively simple formula to calculate intervals. After your first review, it suggests a second review after 1 day. Your third review comes 3 days after your second. Your fourth comes 10 days after your third. From there, each interval increases by a constant multiplier called the "ease factor," which you adjust based on how easy or difficult the card felt.
The problem? This one-size-fits-most approach requires significant user input. The classic system forces you to rate every card on a 1-5 scale (or 1-6 in some implementations), asking questions like "How easy was it to answer this card?" This puts the burden on you to calibrate the scheduling engine. If you rate cards too easily, you'll see them too infrequently and forget. If you rate them too harshly, you'll waste time on cards you already know.
Moreover, older systems don't differentiate between different types of cards in your deck. A medical student might use the same ease ratings for anatomical facts and differential diagnoses, even though these require different review frequencies. Legacy approaches have no concept of card-specific difficulty—only global ease adjustment.
Modern System Innovations
This contemporary approach solves these problems through three key innovations:
1. Automatic Parameter Optimization
Instead of relying on your manual ratings, this system analyzes your entire review history—potentially hundreds or thousands of reviews—and automatically determines the optimal parameters for your learning patterns. The scheduler doesn't ask you whether a card felt easy. It looks at your actual performance history and deduces the card's difficulty mathematically.
This automated approach has profound implications. First, it removes the cognitive load of rating ease. Second, it's more accurate: your history doesn't lie, but your subjective ease rating might. Third, it adapts continuously. As you gain expertise in a subject, the scheduler recognizes that cards are becoming easier and adjusts accordingly. Older systems would require you to manually lower the ease factor.
2. Power Function Forgetting Curve
This system uses a power function rather than an exponential function to model how quickly you forget. This choice is based on extensive empirical data. When researchers fitted different approaches to real user data from thousands of learners, they found that a power function (1 + F × t/S)^C provided a significantly better fit than the exponential curves used in traditional spaced repetition theory.
Why does this matter practically? The power function more accurately predicts your recall probability over long time periods. If you want to maintain 90% how-much-you-remember for a card while minimizing review frequency, this system calculates the optimal interval more precisely than older methods. This is why users of this approach achieve the same how-much-you-remember with fewer reviews.
3. Personalized Difficulty Assessment
Perhaps the most elegant feature of this modern system is how it models card difficulty separately from memory stability. The scheduler recognizes that some concepts are inherently harder to learn, regardless of how many times you've reviewed them. A complex biochemistry pathway will always be harder than a simple vocabulary word.
By incorporating difficulty as an independent variable, this approach can make smarter decisions. A difficult card that you've reviewed many times might have high stability but lower retrievability, warranting more frequent reviews than an easy card with comparable stability. Older systems don't make this distinction.
The Personalization Revolution: How Modern Systems Adapt to You
One of this approach's most underrated advantages is its personalization capabilities. Because it uses machine learning to optimize its parameters, it essentially "learns your learning style."
Different people forget at different rates. Some individuals naturally hold onto information longer; others forget faster. Older systems have no way to account for individual differences—they use the same formulas for everyone. This contemporary method, by contrast, optimizes its core parameters (the weights and constants in its calculations) based on your personal review data.
Consider two medical students using the same anatomy deck. Student A has a naturally better memory and forgets slowly. Student B forgets quickly and needs more frequent reviews. With the older approach, both students would use identical ease factors and intervals. With this modern system, the scheduler optimizes different parameters for each—longer intervals for Student A, shorter ones for Student B—all based on analyzing their actual performance data.
This personalization extends beyond individual differences. The system adapts to how you're studying. If you suddenly review many cards in a single session, it recognizes this and adjusts. If you go on vacation and return to studying after a gap, the scheduler recalibrates. The engine is perpetually learning and optimizing.
Real-World Performance: What the Data Shows
So far, we've discussed this approach in theoretical terms. But what does the data actually say about real-world performance?
Benchmark Results
The most comprehensive comparison of scheduling systems comes from the open-source community, which tested multiple approaches on data from approximately 10,000 real users. The results are striking:
This modern system (version 5) achieves a predictive accuracy (measured by Root Mean Squared Error—RMSE) that significantly exceeds older approaches. More practically, this method with default parameters produces better intervals than the classic system in 91.9% of studied decks. When the scheduler's parameters are optimized specifically for an individual user's data, this modern approach outperforms the older method in 99% of cases.
These aren't marginal improvements. In terms of odds, this represents a shift from "roughly 1 in 12 users would be better off with the older system" to "roughly 1 in 100 users would be better off with the older system."
Even more impressively, independent evaluation by SuperMemo—the original spaced repetition company that created the classic SM-2 method—confirms that this contemporary approach outperforms both the older system and SuperMemo's own modern engine (SM-17) on cross-comparison metrics.
Study Time Reduction
The academic literature supports these benchmarks. Studies in educational technology research show that users of this system can achieve 90% how-much-you-remember rates while requiring 20-30% fewer daily review sessions compared to traditional scheduling approaches. For a student reviewing 100 cards daily with the older system, switching to this modern approach might reduce that to 70-80 cards—a substantial time savings.
The reduction compounds over time. A student spending 30 minutes daily on reviews could theoretically save 6-9 minutes per day, translating to roughly 30-45 minutes saved per week. Over a semester or year of study, these minutes accumulate into hours of reclaimed study time that can be redirected to deeper learning, other subjects, or simply rest and recovery.
How-Much-You-Remember Rates
Critically, this efficiency isn't achieved by sacrificing how-much-you-remember. This modern system maintains performance comparable to or better than older approaches while requiring fewer reviews. This is the key advantage: you're not studying less to save time—you're studying smarter and saving time while maintaining learning outcomes.
Modern Systems vs. Other Approaches: The Competitive Landscape
This contemporary method hasn't emerged unopposed. Other researchers and companies have developed competing modern systems. Understanding how this approach compares to these alternatives provides important context.
SM-17 (SuperMemo's Modern Engine)
SuperMemo has continued developing its proprietary methods, with SM-17 being their current flagship. However, comparative analyses suggest that the modern open-source approach (version 6) outperforms SM-17 on key metrics like cross-comparison and log loss. Moreover, this system has a critical advantage: it's open-source and free. SM-17 requires a SuperMemo subscription and doesn't work with popular apps like Anki.
Other Emerging Approaches
Newer research continues to produce specialized systems. For example, researchers have developed LECTOR, an approach that integrates semantic analysis and concept-based learning. While LECTOR achieves marginally higher success rates in some contexts, it requires significantly more computation and review attempts. This modern method represents the best balance of accuracy, efficiency, and practical usability.
The consensus in the learning science community is clear: this contemporary approach is currently the most advanced open-source, widely-applicable scheduling system available.
Why MintDeck Chose This Modern Approach
If you're considering MintDeck as your learning platform, the choice of this modern system as the underlying engine reflects a commitment to giving you the most effective learning experience possible. By incorporating this approach rather than older systems, MintDeck positions itself at the forefront of educational technology.
For the platform, implementation of this modern method means:
- Smarter scheduling that learns from your performance and adapts continuously
- Reduced study burden while maintaining or improving how-much-you-remember
- Personalization that respects individual differences in learning
- Research-backed results supported by independent benchmarks and academic literature
For you as a user, it means that every minute you spend studying counts more effectively. You'll review cards at the optimal moment—not too soon (wasting time) and not too late (resulting in forgetting). The scheduler handles the complex mathematics of determining that optimal moment, leaving you free to focus on actual learning.
The Settings That Matter: Configuring Your System
While this modern approach removes much of the manual calibration required by older systems, understanding a few key settings will help you optimize your results.
Desired How-Much-You-Remember
The most important setting is your "desired how-much-you-remember" level—typically a percentage between 70% and 95%. This determines the threshold at which the scheduler plans your next review.
If you set this to 95%, the system schedules reviews so that you have approximately a 95% probability of successful recall. Higher targets mean shorter intervals between reviews—more study time but less forgetting. Lower targets mean longer intervals—less study time but higher forgetting rates.
Research suggests that 80-90% represents the optimal balance for most learners. At 95%, the study workload increases enormously with diminishing returns. At 70%, you forget too frequently and waste time on re-learning. The sweet spot for most learners is 80-90%.
Maximum Interval
This setting caps the longest interval the scheduler will suggest. For example, if you set a maximum interval of 36,500 days (100 years), the system might schedule reviews years apart for cards you've mastered completely. Many learners set more practical maximums—180 days for exam preparation, 365 days for long-term knowledge building.
Learning and Relearning Steps
These shorter-term settings (typically measured in minutes to days) determine how the scheduler handles new cards and forgotten cards. This modern approach doesn't modify these short-term steps—they work the same as in older systems. The engine focuses its optimization on long-term interval scheduling.
Common Misconceptions About This Approach
As this modern method gains adoption, several myths have emerged. Let's clarify the facts.
Misconception 1: "This system is too complex to understand"
While the mathematical foundation involves neural networks and advanced statistics, using this approach requires no technical knowledge. You set a desired how-much-you-remember percentage and let the scheduler handle the rest. This modern system is actually simpler to use than older approaches because you don't need to manually rate ease for every card.
Misconception 2: "This method requires massive amounts of data to work"
While this system improves with more data (this is how machine learning works), it performs well from the start. Even with just a few dozen reviews, this approach produces better scheduling than the older system's default parameters. As you accumulate more review data, the scheduler's personalization improves.
Misconception 3: "This approach is proprietary and experimental"
This contemporary system is completely open-source and free. It's based on peer-reviewed research and has been tested on data from thousands of real users. Multiple independent platforms have integrated this method successfully. It's battle-tested and production-ready.
Misconception 4: "This system will make you forget more"
Because users of this modern approach can achieve the same how-much-you-remember with fewer reviews, some assume performance suffers. The data shows the opposite: this system maintains performance while improving efficiency. At equal how-much-you-remember levels, it requires fewer reviews. At equal review loads, it maintains higher performance.
The Future of Spaced Repetition: Where This Approach Is Heading
This modern system continues evolving. The research community working on newer versions is exploring several promising directions:
- Improved semantic understanding: Integrating natural language processing to understand card meaning and adjust difficulty assessments
- Multi-dimensional learning: Accounting for the fact that different knowledge types (facts vs. procedures vs. concepts) might require different scheduling
- Cross-deck optimization: Analyzing performance across all your decks to optimize global parameters better
- Integration with AI tutoring: Combining this system's scheduling with AI-generated explanations and personalized teaching
While these features remain in development or early research phases, they point toward a future where your learning platform doesn't just schedule reviews optimally—it personalizes every aspect of your learning experience.
Practical Tips for Maximizing Results
Now that you understand how this modern approach works, here are practical strategies to get the most from the scheduler:
1. Write Clear, Atomic Cards
This system is only as good as the cards you feed it. Each card should test one concept. Instead of "Explain photosynthesis," use atomic cards: "What is the primary function of the thylakoid?" and "What are the products of the light-dependent reactions?" Clear cards give the scheduler better data for calibrating difficulty.
2. Keep Your Target How-Much-You-Remember Consistent
Resist the temptation to constantly adjust your target performance percentage. This system works best when the scheduler optimizes to a consistent target. Pick a level (80-90% is recommended), use it for at least a few hundred reviews, and let the engine adapt. If you constantly change it, you're disrupting the optimization process.
3. Review Consistently
This modern approach adapts to your review patterns. Regular, consistent reviewing allows the scheduler to build an accurate model of your memory. Sporadic reviewing with large gaps confuses the optimization and reduces effectiveness. Try to maintain a regular review schedule, even if it's just 15 minutes daily.
4. Trust the System on Difficult Cards
One common mistake is overriding the scheduler's recommendations on cards you find difficult. If this system suggests a hard card in two days and you think it should be sooner, resist the urge to manually move it. Let the engine determine the timing—that's what it's optimized for. Your subjective feeling about difficulty is less accurate than the scheduler's calculation based on your history.
5. Avoid Excessive Customization
While this modern approach allows some parameter tuning, most users achieve better results with default settings. The defaults are based on analysis of thousands of learners and represent the optimal starting point. Only customize if you've used the system for several months and have a specific reason to adjust.
Why This Matters for Your Learning Journey
If you're investing time in learning through spaced repetition, the scheduling engine powering your reviews directly impacts your return on that investment. A 20-30% reduction in study time might sound modest, but compounded over months or years of learning, it represents substantial time savings.
More importantly, using a modern approach like this ensures that your study time is spent optimally. Every moment of review is timed to have maximum learning impact. You're working smarter, not just harder.
For MintDeck users, implementing this modern system signals that the platform prioritizes learning science over simplicity. The platform could have used simpler, legacy approaches that are easier to explain or implement. Instead, choosing this contemporary method demonstrates a commitment to giving learners the most effective tool available.
Whether you're studying for medical licensing exams, learning a new language, building professional certifications, or engaging in lifelong learning, using a platform powered by this modern system means you're harnessing decades of memory research and the latest machine learning techniques to optimize how you learn.
Conclusion: The Next Generation of Scheduling Is Here
This contemporary approach represents a genuine paradigm shift in spaced repetition technology. It replaces static formulas with dynamic, machine-learning-based optimization. It removes the burden of manual calibration while improving accuracy. It personalizes scheduling to your individual memory patterns while maintaining simplicity for end users.
The evidence is compelling: this modern system outperforms the 40-year-old SuperMemo method in nearly all cases while reducing study burden and maintaining how-much-you-remember. It's open-source, free, and backed by independent research. Major learning platforms—from Anki to RemNote to specialized iOS apps—have embraced this approach as their scheduling engine.
For learners, the question isn't whether this modern system is better than older approaches. The data conclusively answers that. The relevant question is: why would you use anything else?
By choosing a learning platform like MintDeck that implements this modern scheduling method, you're choosing to optimize how you learn. You're ensuring that every flashcard review serves its intended purpose—strengthening memory at exactly the right moment. In a world where knowledge is increasingly valuable and time is increasingly scarce, that optimization matters.
The most advanced scheduling engine isn't just a technical curiosity—it's the next generation of learning tools. And it's available to you today.
Key Takeaways
- This modern system outperforms older approaches in 91.9-99% of cases through machine learning optimization and personalized parameter adjustment
- The Three-Component Model (Difficulty, Stability, Retrievability) provides a more accurate framework for memory than traditional methods
- Study efficiency gains of 20-30% are achievable while maintaining or improving how-much-you-remember rates
- Automatic optimization eliminates the need for manual ease rating calibration required by older systems
- Open-source and free, this approach represents the cutting edge of memory science and machine learning for learning applications
- Personalization ensures that schedules adapt to individual learning patterns and forgetting rates
- Research-backed results from independent benchmarks and academic studies demonstrate this approach's superiority
- Practical implementation requires minimal user configuration—simply set desired how-much-you-remember and let the scheduler adapt
- Future development promises semantic understanding, multi-dimensional learning models, and deeper AI integration